Graph Theory: Part III (Facebook)
In the first and second parts of my series on graph theory I defined graphs in the abstract, mathematical sense and connected them to matrices. In this part we'll see a real application of this connection: determining influence in a social network.
Recall that a graph is a collection of vertices (or nodes) and edges between them. The vertices are abstract nodes and edges represent some sort of relationship between them. In the case of a social network the vertices are people and the edges represent a kind of social or person-to-person relationship. "Friends of," "married to," "slept with," and "went to school with" are all example of possible relationships that could determine edges in a social graph.
So, right away, you can see how this applies to Facebook. They have a huge collection of just this sort of data: who is friends with whom, who is in a relationship with whom, who is married to whom, who went to college with whom, etc. Can anything useful be done with this?
What Can Be Done With a Social Graph
Let's step back and think like a marketer for a second. Facebook, thanks to the newsfeed, is essentially a word-of-mouth engine. Everything I do, from installing applications to commenting on photos, is broadcast to all my friends via the newsfeed. Intuitively, however, we know that some people are just more influential than others.
If my cool friend writes a note about an awesome new shop he found in the Lower Haight I'm probably going to pay more attention. People like this, who are influential and highly connected, are a marketers dream. If I can identify and target these people, "infecting" them with my marketing, I'll get ten times my return than I would going after random people in my target demographic.
Facebook is almost certainly doing something like this already with respect to the newsfeed. They process billions of newsfeed items per day. How do they know which messages are most important to me? Well, it stands to reason that the messages that are most important to me are the ones from the people who are most important to me. So, as Facebook, I want to be able to calculate the relative level of importance of a person's friends and use that measurement to weight whether their newsfeed items get displayed for their friends.
There are several problems. Can we come up with a good measure of social importance or influence? Are there multiple measures, and if so, what are their relative merits?
Measurements of Social Influence
Let's start simple. One way to measure influence is connectivity. People who have lots of friends tend to have more influence (indeed, it's possible they have more friends precisely because they are influential). Recall from the first part that the degree of a node in a graph is the number of other nodes to which it is connected. For a graph where "is friends with" is the edge relationship then the degree corresponds to the number of friends.
Degree Centrality
Let's call this influence function Id ("d" for degree). Thus, if p is a person then Id(p) is the measure of their influence. Mathematically we get

The main advantage of this is that it's dead-simple to calculate. If you represent your graph as an adjacency matrix, as in the second part of this series, then the influence of a node is just the row-sum of the corresponding row — an operation which is very fast and easily paralleizable.
The downside of this is that its naive. Consider the following graphs.
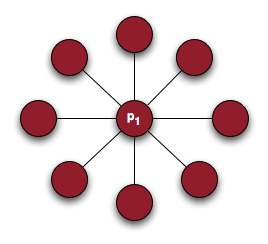
Single person with high degree
Single person low degree but high connectivity
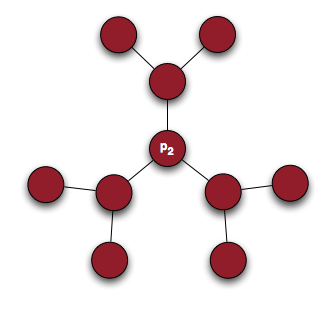
Using Id as a measure of influence the first person, p1, has a higher measure of influence because they are directly connected to eight people. The second person, p2, however, has the potential to influence up to 9 people. This happens in the real world, too. Consider a corporate hierarchy in a large company. The CEO only has direct relationships with his board, the VPs, and maybe a few other employees. He is undeniably more influential than an administrative assistant to the deputy regional director of sales for Southern Montana and yet might have fewer direct connections.
Using Eigenvalues
One way to capture this sort of indirect influence is to use a measurement called eigenvalue (or eigenvector) centrality. The idea is this: a person's influence is proportional to total influence of the people to whom he is connected. We'll call this influence measure Ie.
Let's say I'm the CEO at X Corp. There are four VPs each of whom has an influence of 5 and these are the people to whom I am connected directly. Then this measure says that there is some number λ such that 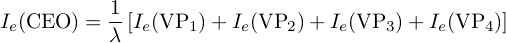
λ determines how much influence people share with each other through their connections. If λ is small then the CEO has a lot of influence, if it is large then he has little. How do we calculate λ?
Let G be a social network or social graph, where vertices are people and edges are some sort of social relationship, and let A be the adjacency matrix of G. If there are N people in the social network labeled p1, p2,... then we can generalize the above and say that
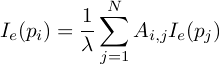
Remember that Ai,j is 1 if pi and pj are joined by an edge and 0 otherwise. It's also important to notice that λ is a function of the graph not of any individual node.
If we call xi = Ie(pi) then we can form a vector x whose ith coordinate is the influence of the ith person. We can rewrite the above equation using vectors and matrices, then, as follows:
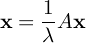
or
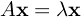
Eigenvalue Problem
If you remember from the second part of this series this is the classical eigenvalue equation (hence the name of this influence measure).
Calculating someone's influence according to Ie is therefore equivalent to calculating what is known as the "principal component" or "principal eigenvector." Luck for us there are tons of eigenvalue algorithms out there.
The Power Method
The easiest, but not necessarily the most efficient, way of calculating the principal eigenvalue and eigenvector is called the power method. The idea is that if you take successive powers of a matrix A, normalize it, and take successive powers then the result approximates the principal eigenvector.
You can read the mathematical justification for why this at Wikipedia. Here is some Python code which takes as its input the adjacency matrix of a graph, an initial starting vector, and the level of error you're willing to permit:
from numpy import *
def norm2(v):
return sqrt(v.T*v).item()
def PowerMethod(A, y, e):
while True:
v = y/norm2(y)
y = A*v
t = dot(v.T,y).item()
if norm2(y - t*v) <= e*abs(t):
return (t, v)
The upside to using this method is that it is relatively easy to compute (Google uses a variant of this to calculate PageRank, for example) and that it encompasses more subtleties about how nodes possibly influence each other. The downsides are mostly technical: there are certain situations where the power method fails to work.
Other Measures
There are other measure, too. The two most common are called betweenness and closeness.
Without going into detail, the betweenness of a node P is average number of shortest paths between nodes which contain P. So, nodes that are in high-density areas where most nodes are separated by one or two degrees have a high betweenness score. The closeness of a node P is the average length of the shortest path from P to all nodes which are connected to it by some path.
Both of these measurements are fairly sophisticated and difficult to calculate for large graphs.
Experimental Measurement
The downside to all these measure is that it only takes into account the topology of the graph. That is, it ignores the fact that the nodes, as people, are performing actions. In the case of Facebook we can measure influence directly by measuring how activity spreads throughout the network. Let's say we have a person P with friends F1, F2, F3, etc. As Facebook we send out a message on behalf of person P to his friends and count how many act on the message.
Statistically we can model this using a random variable. Let Xi be the number of people "influenced" by a message sent on behalf of pi, the ith person on our network. We can then calculate the expected value of Xi.
We can then take into account information from the profile data and answer questions like "What is the expected number of people this person will influence given he is a male, 32, a marketing executive who graduated from Harvard with 42 friends and 102 wall posts?"
Conclusion
These techniques work on any graph, including the social graph Facebook has. When you have a graph as complete as Facebook you're able to do a lot of interesting stuff. Imagine I'm a marketer who wants to have a sponsored newsfeed item. Facebook can charge a premium because they're able to target the influencers by using techniques like the ones above.
Of course I can't say whether Facebook is using some, none, or all of the techniques I described. But that doesn't mean application developers can't. By keeping track of who influences who you can use these techniques to maximize your exposure. Fancy that!